新一代人工智能与预训练大模型导论-3
大模型的数据、算法和算力
机器是怎么学习的
1959年美国计算机科学家Arthur Samuel提出了“机器学习”的概念并定义为“让计算机在没有显著编程的情况下,具备自我学习的能力”。而Tom Mitchell则进一步定义为“能从经验中学习并提高表现的计算机程序”。
没有显著编程实际上指的是没有直接的公式推得结果,而是用数据驱动(观察-归纳)方法解决。
机器学习通俗说法:对于特定任务,根据现有数据猜测背后的规律,可以计算,在现有数据有良好的表现,从而应用于新的数据。
| 构成 | 比喻 |
|---|---|
| 待解决问题 | 锁(特定任务+经验) |
| 模型 | 钥匙本身 |
| 优化方法 | 打磨钥匙的手段 |
| 目标函数 | 钥匙和锁的匹配程度 |
有监督学习
是机器学习的主要方法,使用有标记的训练数据来交模型如何理解数据背后的规律。在训练过程中,模型会尝试学习输入数据和其对应的正确输出(标签)之间的关系。由人类专家优先定义,”有多少人工,有多少智能“
无监督学习
是机器学习的另一类方法。其模型被训练来发现输入数据中的隐藏规律。不需要标注的数据集。
无监督虚席的传统命题包括了聚类、降维、异常检测等,前沿是生成模型。生成模型可以理解数据当中的统计规律,从而给出任意多相似的新数据。
自监督学习
是机器学习的一类前沿方法,是一种特殊类型的无监督学习。模型通过利用数据本身信息自动生成标签,不依赖外部提供。适用于标签数据稀缺或获取标签成本高昂的场景。
模型需要学习如何根据数据的上下文重建整个数据样本。或者进行额外处理,让模型猜测处理手段的类型或者具体方式。
将前叙比喻细化
人工神经网络有多神经
连接主义
认为人工智能应该模仿人类的大脑,利用多神经元来实现智能。起源于“感知机”模型。
从数学方法运算,在隐藏层中引入线性(或者非线性)的运算再到。通过调整各个参数而改变输出。
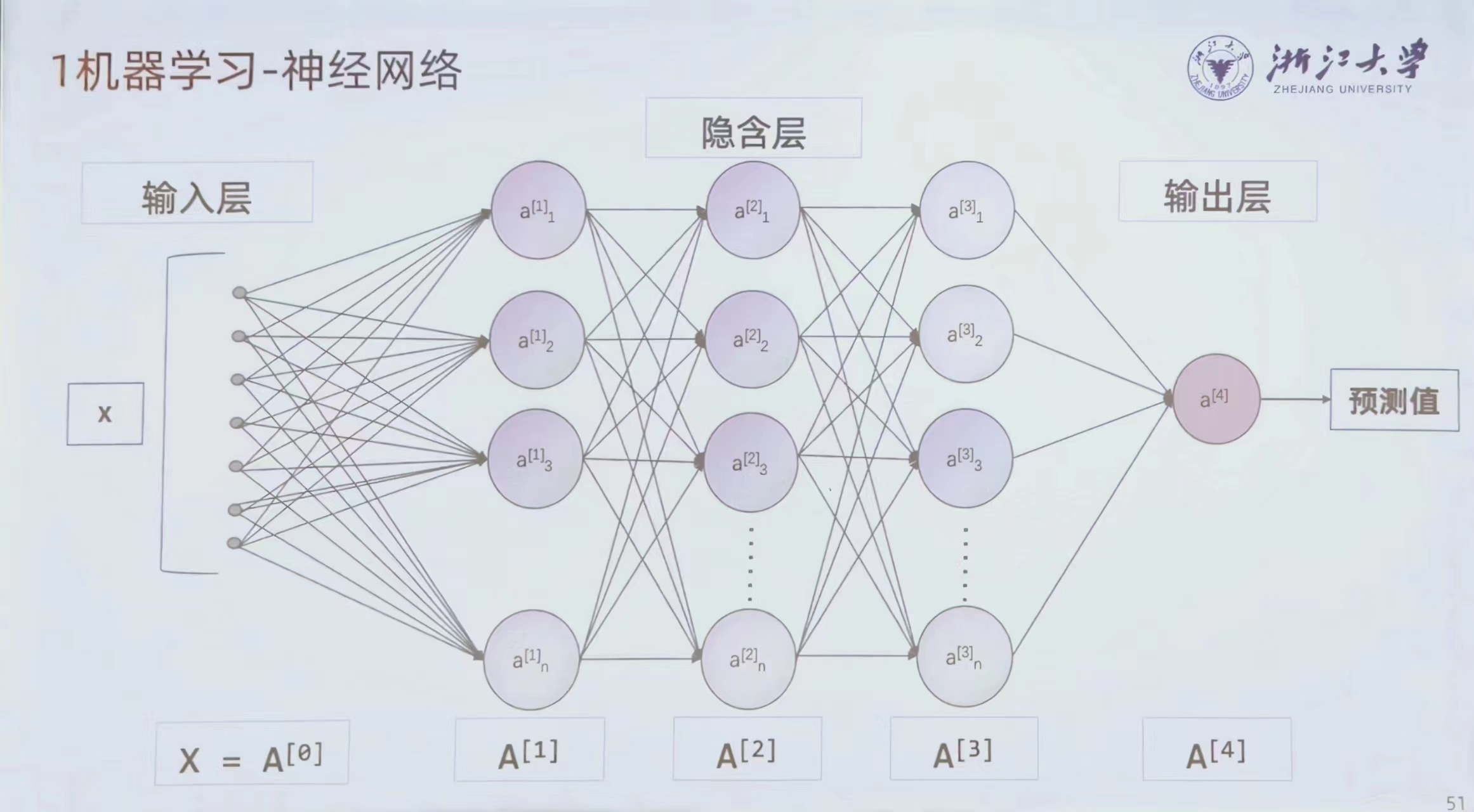
神经网络:一系列把输入进行系数相乘和相加,之后用非线性变换并输出的运算。
大模型使用什么数据
ImageNet包含了超过1400万张全尺寸标记图片,21841类,是深度崛起的关键数据集。
LAION-5B是目前已开源最大规模的多模态文本图像训练集,共有80T数据,拥有超过50亿个图像和文本对。
数据之大不在数量,更在种类之多。港中文使用Meta-Transformer将多种种类的数据统一,不同模态的数据要融会贯通。
数据基本组成的相互依赖程度不同,数据产生的原理也不同。人类产生的数据的复杂度比自然产生的低。
高质量数据非常宝贵,OpenAI从《纽约时报》获取训练数据,Google通过Photobuchet提供网盘服务保留了大量照片、视频,被OpenAI花10亿美金买走。因此高质量的数据终会耗尽,根据EpochAI的报告,预计高质量语言数据将会很快被耗尽,预测2040年,机器学习模型的发展由于缺乏训练数据,有大约20%的几率会显著减慢。
不同模态数据的可用数量不同,如文本数据可能有上万亿词汇,视频可能有数十亿小时,但是3D模型只有数千万个,音频数据未知……
当我们聊“卡”时其实在聊什么
浮点数(实数)运算需要对应器件,一个32位的加法器需要2200个晶体管,乘法器需要更多晶体管。
一个CPU包含约300亿个晶体管,CPU支持x86,x86-64等指令集,CPU时通用的,最终用于运算的晶体管数量不多,因此要规划不同运算区。因此,CPU有的时候并不一定适合做运算。
而显卡不像CPU要处理那么多,GPU只需要做好浮点数的加减乘除即可,还有矩阵的各种运算,纹理的采样指令。计算效率比CPU更高
眼睛、游戏和科学计算
2D、3D内容的渲染都是依赖数值计算,计算出每个像素的数值。工程领域、科学计算里有很多任务和图像处理高度类似,大部分还是数值计算。流体力学计算、结构力学计算、电路分析等,最终都会变成复杂庞大的数值计算。算力是大部分学科的根基。
算力与大模型
CUDA是一种专有的并行计算平台和应用程序编程接口,允许软件使用图形处理单元进行运算。大模型中的计算,大部分还是上述加法和乘法运算。TFLOPS是计算单位,每秒计算10的12次方浮点数运算。
A100,32位浮点数 19.5TFLOPS,Tensor Core 156FLOPS
H200,32位浮点数 67TFLOPS, Tenser Core 989TFLOPS
Transformer与缩放法则
Token与自回归
将数据切成多份,再多份学习,多份生成。每一份就是一个Token,切块的操作就是Tokenization,意义在于把难以整体处理的数据变成一个个容易处理的小元素(Token)。
Transformer是对于现有的文本,预测下一个单词(Token)是什么